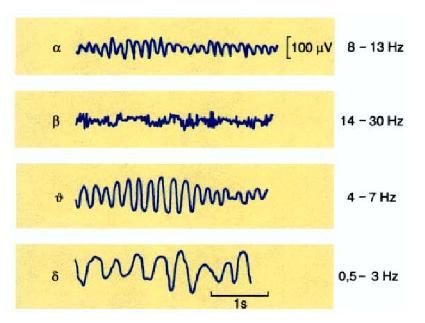
Abb. 1: Verschiedene Frequenzbereiche von Wach- bis Schlafzustand. Deetjen, Speckmann, (1992)
Die klassische Schlafstadienanalyse basiert auf der Untersuchung von Gehirnströmen. Dabei bilden charakteristische Gehirnwellen für den Wachzustand bzw. für den Schlaf die Grundlage dieser Methode. An ausgewählten Elektroden (typischerweise C3 und C4) werden die zu untersuchenden Signale aufgenommen und anschließend ausgewertet. Die einzelnen Signale ergeben sich als Überlagerung von mehreren Frequenzen. Man unterscheidet zwischen 5 verschiedenen Frequenzbereichen: α, β, ϑ, δ und γ. Anhand der Zusammensetzung des aufgezeichneten Signals, das heißt durch Bestimmung der dominierenden Frequenzen, kann man dann feststellen, ob sich der Proband im Wachzustand bzw. in einem der Schlafzustände befindet. Darüber hinaus lassen sich anhand der Aufzeichnung Aussagen über bestimmte Schlafaktivitäten (z.B. Träume) und Abnormalitäten des Schlafes treffen. In Tabelle 1 sieht man, dass die Frequenz vom Wachzustand zum Tiefschlaf stark abnimmt.
| Wellen | Frequenz in Hz | Amplitude in μV | Auftreten |
|---|---|---|---|
| β | 14 - 30 | 5 - 50 | vorwiegend im Wachzustand |
| α | 8 - 13 | 20 - 120 | bei Ruhe |
| ϑ | 4 - 7 | 20 - 100 | im Schlaf |
| δ | 0,5 - 3 | 5 - 250 | im Tiefschlaf |
| γ | 31 - 100 | -10 | beim Lernen |
Tab. 1: EEG-Frequenzen von Wach- und Schlafzustand. | |||
In der Abbildung 1 sind die Frequenzunterschiede der verschiedenen EEG-Wellen noch einmal graphisch gegenübergestellt. Man erkennt hier auch die Zunahme der Amplituden vom Wachzustand zum Tiefschlaf.
| |||
Abb. 1: Verschiedene Frequenzbereiche von Wach- bis Schlafzustand. Deetjen, Speckmann, (1992) | |||
Der menschliche Tagesrhythmus reguliert unbewusst wichtige physiologische Funktionen des Körpers. Erhöhte Stoffwechselaktivität, regenerative Prozesse und Konsolidierung von Gedächtnisinhalten finden z.B. vornehmlich im Schlaf statt. Bestimmend für diesen zirkadianen Rhythmus sind vor allem geophysikalische und soziale Gründe. Allerdings unterliegt der menschliche Körper auch ohne äußere Einflüsse einem Rhythmus, der dann nicht 24 Stunden, sondern circa 25 Stunden beträgt. Der Schlaf nimmt bei diesem periodischen Zyklus eine wesentliche Rolle ein. Permanenter Schlafentzug führt abhängig vom Alter rasch zu schweren körperlichen Schädigungen und schließlich zum Tod.
Man unterteilt den Schlaf in 5 Phasen:
In Abbildung 2 kann man die Korrelation von Augenbewegungen (rapid eye movements mittels Elektrookulogramm EOG gemessen) und Muskelzuckungen (mittels Elektromyogramm EMG gemessen) während eines Traumes sehen. Weiterhin erkennt man deutlich, wie Artefakte (äußere Störungen) die theoretisch klaren Signale verrauschen, so dass eine Zuordnung der Signaleabschnitte zu den Schlafstadien nicht immer möglich ist. So lassen sich z.B. die Signale der Schlafzustände A, B und C (entsprechen 1., 2. bzw. 3. Schlafphase) an manchen Stellen optisch nur schwer unterscheiden.
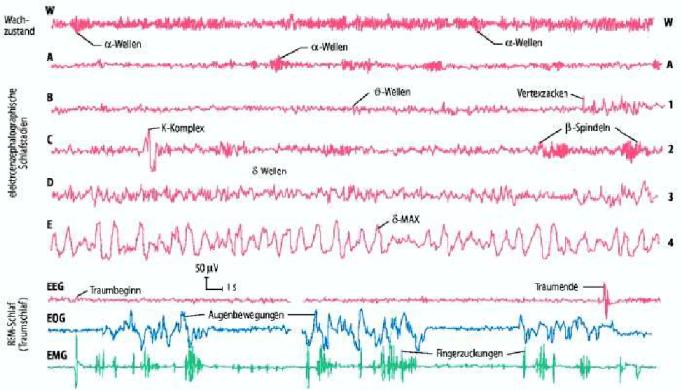 | |||
Abb. 2: Signalausschnitte einer Schlafstudie. Schmidt, Thews, (1997) | |||
Die Schlafphasen 1-4 heißen auch NREM-Schlaf (oder non-REM Schlaf). Die einzelnen Schlafstadien werden 3 bis 5 mal pro Schlaf in der Reihenfolge 1,2,3,4,3,2,1,REM,1,2,3,4,3,2,1,REM,... durchlaufen. Ein normaler Schlafzyklus (von REM zu REM) eines Erwachsenen dauert ungefähr 90 Minuten. Mit steigender Schlafdauer nimmt die Häufigkeit des Auftretens der Schlafphasen 3 und 4 ab und die Dauer der REM-Phasen nimmt zu. Es wird vermutet, dass in den Tiefschlafphasen 3 und 4 die Verarbeitung von Gedächtnisinhalten am stärksten ausgeprägt ist. Deshalb nennt man die ersten zwei Zyklen, in denen diese Phasen auftreten, Kernschlaf. Die nachfolgenden Zyklen werden als Füllschlaf bezeichnet. Abbildung 3 zeigt, dass nur am Anfang des Schlafes die Tiefschlafphasen erreicht werden.
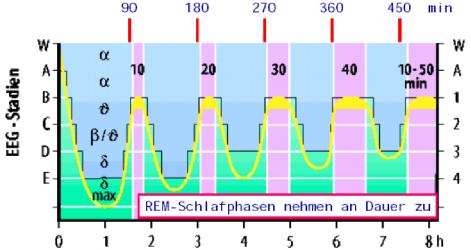 | |||
Abb. 3: Schlafphasen des Schlafes eines gesunden Erwachsenen. Schmidt, Thews, (1997) | |||
Die Schlafdauer und der Anteil an REM-Schlaf hängt von Lebensalter ab. Neugeborene benötigen durchschnittlich 16 Stunden Schlaf, von denen 50 % REM-Schlaf ausmachen. Erwachsene schlafen hingegen circa 8 Stunden von denen 25 % REM-Schlaf sind. Mit steigendem Alter nimmt der REM-Anteil kontinuierlich ab (siehe Abbildung 4). Die Gesamtschlafdauer hingegen nimmt zunächst nur bis zum Alter von 40 Jahren ab, steigt dann bis zum Alter von 60 Jahren und fällt erst in höheren Lebensjahren noch weiter ab. Bei älteren Menschen verteilt sich die Gesamtschlafdauer auf mehrere Schlafzeiten, da sie oft nicht länger als 5 Stunden zusammenhängend schlafen können.
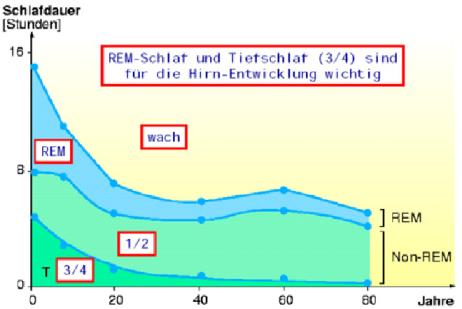 | |||
Abb. 4: Funktionelle Zusammenhang von Alter und REM-Schlafanteil. Schmidt, Thews, (1997) | |||
Neben charakteristischer Gehirnwellen zeichnet sich der REM-Schlaf auch durch die nur dort auftretenden rapid eye movements und Bewegungen der Nackenmuskulatur, die mittels Elektrookulogramm (EOG) bzw. Elektromyogramm (EMG) bestimmt werden. Im REM-Schlaf findet vor allem die Konsolidierung von Gedächtnisinhalten statt. Außerdem sind Träume im REM-Schlaf konkreter und emotionaler als im NREM-Schlaf. Der REM-Schlaf wird auch als paradoxer Schlaf bezeichnet, NREM-Schlaf als orthodoxer Schlaf. Wie in Abbildung 5 zu sehen ist, lässt sich der REM-Schlaf anhand der EEG-, EOG- und EMG-Signale eindeutig bestimmen.
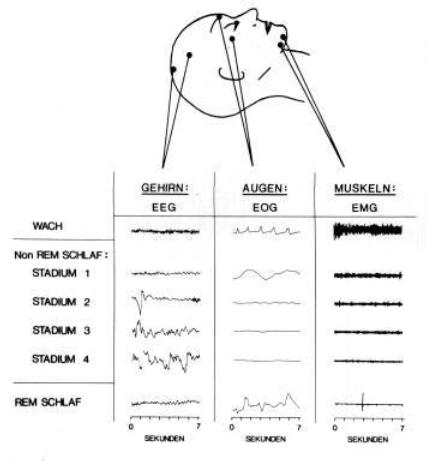 | |||
Abb. 5: Gegenüberstellung der EEG-, EOG- und EMG-Signale während der verschiedenen Schlafphasen. Borbély A., (1998) | |||
In der Natur gibt es viele komplexe Prozesse, die auf den ersten Blick nicht einfach zu verstehen sind. Das Wetter ist beispielsweise ein solcher komplizierter Prozess. Aussagen über das Verhalten dieser Prozesse sind schwer zu treffen. Es wären dazu mathematische Methoden hilfreich, die Prozesse formal beschreiben. Zunächst läßt sich jedem zeitabhängigen Prozess ein Zustand zu einem bestimmten Zeitpunkt zuordnen. In dem Wetterbeispiel hieße das: Jetzt befindet sich das Wetter in einer "Besserungsphase", und danach gibt es einen Wetterumschwung mit dem eine "Verschlechterungsphase" beginnt. Die Zustände in dem Beipiel sind "Besserungsphase" bzw. "Verschlechterungsphase". Diese Zustände sind abhängig von der Problemstellung und müssen deshalb individuell definiert werden. Das Eintreten eines Zustandes wird meist von vielen Faktoren charakterisiert. Beim Wetter spielen z.B. Luftdruck, Temperatur, Windgeschwindigkeit, etc. eine Rolle. Mit der Kenntnis des aktuellen Prozesszustandes und der vorliegenden Faktoren ließen sich nun die Folgezustände des Prozesses statistisch berechnen und somit der gesamte Prozess simulieren. Das Problem dabei liegt in der Bestimmung des aktuellen Prozesszustandes. Bei vielen realen Prozesse sind diese Zustände nicht bekannt. Beim Wetter z.B. kann man nicht genau feststellen, ob es sich in einer "Besserungsphase" oder "Verschlechterungsphase" befindet. Obwohl für einen Moment die Sonne scheint, könnte sich das Wetter trotzdem weiter verschlechtern. Die einzige Information über solche Prozesse sind die Faktoren, die messbar sind. Diese können auch als Signale aufgefaßt werden, die von einem Prozesszustand emittiert werden. Das heißt, die zustandsbestimmenden Faktoren werden nach außen weitergeleitet. Gesucht ist also ein Modell, mit dem anhand dieser Signale die eigentlich interessanten "versteckten" (weil unbekannt bzw. nicht direkt messbar) Zustände statistisch bestimmbar sind. Hidden Markov Modelle (HMMs) ermöglichen eine solche Modellierung. Der Name leitet sich aus der Tatsache ab, dass die gesuchten Zustände "versteckt" (hidden) sind.
Die mathematische Grundlage von HMMs sind Markov-Ketten. Diese kann man mit deterministischen endlichen Automaten vergleichen.
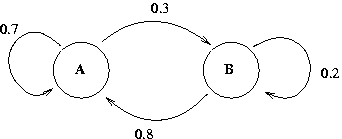 | |||
Abb. 6: Markov-Kette als endlicher Automat dargestellt. Die Pfeile von und zu den Zuständen A und B geben die Übergangswahrscheinlichkeiten an. | |||
Die Dynamik der Zustände, das heißt, die Reihenfolge der Zustände und die Erzeugung der beobachteten Signale sind stochastisch. Somit kann man HMMs auch als doppelt stochastische Prozesse beschreiben. HMMs liefern als Ergebniss eine Zustandsfolge, die mit größter Wahrscheinlichkeit eine beobachtete Signalfolge erzeugt.
Die Zustandsfolgen werden mit einer diskreten Folge von
Zustandsvariablen
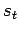 modelliert:
modelliert:
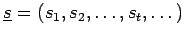 .
.
Dabei können die
verschiedene Zustände einnehmen:
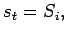 wobei
wobei
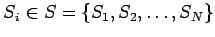 .
.
Nun kann man die Wahrscheinlichkeit angeben, mit der ein Zustand
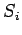 zum Zeitpunkt
zum Zeitpunkt
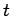 in den Zustand
in den Zustand
 wechselt. Diese Wahrscheinlichkeiten stellen den ersten stochastischen
Teil des Verfahrens dar.
Betrachtet man dazu alle vorangegangenen Zustände erhält, man die
allgemeine Markov-Bedingung (Markov-Prozesse n-ter Ordnung).
Diese stellt die Wahrscheinlichkeit
wechselt. Diese Wahrscheinlichkeiten stellen den ersten stochastischen
Teil des Verfahrens dar.
Betrachtet man dazu alle vorangegangenen Zustände erhält, man die
allgemeine Markov-Bedingung (Markov-Prozesse n-ter Ordnung).
Diese stellt die Wahrscheinlichkeit
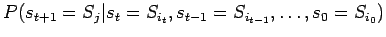
dar, mit der eine bestimmter Zustand zu einem gegebenen Zeitpunk angenommen wird, allerdings unter der Voraussetzung, dass zu allen vorangegangenen Zeitpunkten bestimmte Zustände vorlagen. Eine wichtige Eigenschaft von Markov-Ketten besteht in einem beschränktem Gedächtnis. Das heißt, man betrachtet nur den aktuellen Zustand und den nachfolgenden Zustand. Solche Ketten heißen auch stationäre Markov-Ketten (Markov-Prozesse erster Ordnung). Die entsprechende stationäre Markov-Bedingung stellt ebenfalls die Auftrittswahrscheinlichkeit eines Zustandes zum Zeitpunkt t+1 dar, allerdings nur unter der Voraussetzung, dass zum unmittelbar vorangegangenen Zeitpunkt t ein bestimmter Zustand vorlag. Diese Übergangswahrscheinlichkeiten
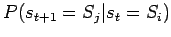
reduzieren die Komplexität der Wahrscheinlichkeitsbetrachtung. Die Vereinfachung ist fundamental für eine effiziente Berechnung.
Zur besseren Handhabbarkeit werden die Übergangswahrscheinlichkeiten
in einer N×N-übergangsmatrix
 gespeichert:
gespeichert:
 mit
mit
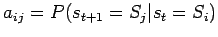 .
.
Die Wahrscheinlichkeiten, dass die Zustände zum Zeitpunkt t=0 einen bestimmten Wert annehmen,
werden in einem separaten Vektor
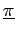 aufgeführt:
aufgeführt:
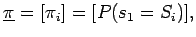 mit
mit
Die Trennung zwischen äußerlich beobachtbarem Signal und innerem Zustand wird durch die Einführung von Emissionswahrscheinlichkeiten realisiert. Die einzelnen Zustände emittieren die verschiedenen Signale mit unterschiedlicher Wahrscheinlichkeit, wobei die Summe der Wahrscheinlichkeiten natürlich 1 ergibt. Formal bedeutet dies, dass ein Signal als Symbol dargestellt wird. Für diskrete Signale ergibt sich eine Menge von Symbolen:
 .
.
Kontinuierliche Signale werden als Vektor
 dargestellt.
Emissionswahrscheinlichkeiten (auch Ausgabewahrscheinlichkeiten genannt)
stellen den zweiten stochastischen Teil des Modells dar.
Sie werden ebenfalls zur besseren Handhabung in einer Matrix gespeichert:
dargestellt.
Emissionswahrscheinlichkeiten (auch Ausgabewahrscheinlichkeiten genannt)
stellen den zweiten stochastischen Teil des Modells dar.
Sie werden ebenfalls zur besseren Handhabung in einer Matrix gespeichert:
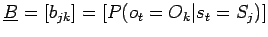 (diskret),
(diskret),
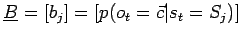 (kontinuierlich).
(kontinuierlich).
Beliebige Verteilungen können im kontinuierlichen Fall mittels Mischverteilungen approximiert werden:
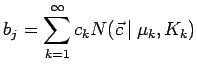 .
.
Die "versteckten" Zustände gaben diesem Modell den Namen Hidden Markov Modell, denn man kann nur mit einer bestimmten Wahrscheinlichkeit, aber nicht mit Gewissheit von einem gegebenen Signal auf den emittierenden Zustand schließen. Dies liegt daran, dass ein Zustand potentiell alle möglichen Signale emittieren kann, jedoch mit unterschiedlicher Wahrscheinlichkeit. Formal kann man nun ein HMM als Tripel
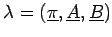
definieren.
Bei der Anwendung von HMMs auf reale Problemstellung lassen sich 3 wichtige Aufgaben unterscheiden:
P(O | λ) gibt an mit welcher Wahrscheinlichkeit ein λ die betrachtete
Observationsfolge generiert. Diesen Wert kann man verwenden, um die Qualität eines
Modells zu überprüfen. Das heißt, es wird getestet, wie sich das Modell bei realen
Eingabewerten verhält. Weiß man, dass eine bestimmte Zustandsfolge eine bestimmte Signalfolge
erzeugt (z.B. aus Experimenten), dann sollte ein HMM für diese Werte eine hohe
Gesamtproduktionswahrscheinlichkeit haben. Ist dies nicht der Fall, wurde das Modell
mit falschen Start- oder Übergangswahrscheinlichkeiten modelliert.
Weiterhin kann man diesen Wert als Basis von Klassifikationsentscheidungen nutzen.
Dazu erstellt man für jede Klasse
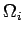 ein eigenes HMM
ein eigenes HMM
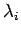 .
Nun bestimmt man für eine gegebene Observationsfolge
.
Nun bestimmt man für eine gegebene Observationsfolge
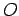 die Produktionswahrscheinlichkeiten mit
die Produktionswahrscheinlichkeiten mit
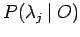
und weist
der Klasse
zu, für die die zugehörige Produktionswahrscheinlichkeit maximal ist.
Eine sehr einfache aber rechenintensive Methode, die Produktionswahrscheinlichkeit zu berechnen, lautet wie folgt:
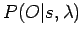 .
.
 .
.
Man berechnet also die Wahrscheinlichkeit
, mit der eine Zustandsfolge eines HMM die gesuchte Observationsfolge
erzeugt. Da das Auftreten einer Zustandsfolge auch statistisch ist (das heißt,
ein HMM nimmt mit einer bestimmten Wahrscheinlichkeit
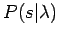 eine Zustandsfolge an), müssen die Observationswahrscheinlichkeiten einer
Zustandsfolge auch noch mit der Wahrscheinlichkeit multipliziert werden,
mit der die Zustandsfolge überhaupt eintritt.
Die Komplexität dieses Algorithmus ist jedoch mit
eine Zustandsfolge an), müssen die Observationswahrscheinlichkeiten einer
Zustandsfolge auch noch mit der Wahrscheinlichkeit multipliziert werden,
mit der die Zustandsfolge überhaupt eintritt.
Die Komplexität dieses Algorithmus ist jedoch mit
 exponentiell und somit nicht für praktische Anwendungen geeignet.
exponentiell und somit nicht für praktische Anwendungen geeignet.
Dieses Verfahren basiert auf dem dynamic programming Ansatz. Es ist wesentlich schneller als die brute force Methode. Der Forward-Algorithmus verwendet die Markov-Eigenschaft des begrenzten Gedächtnisses: der Zustand zum Zeitpunkt t+1 ergibt sich aus der Betrachtung aller N Zustände (nur) zum Zeitpunkt t. Die Berechnungsvorschrift lässt sich wie folgt zusammenfassen:

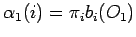
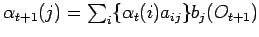
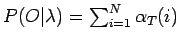
Dabei sind die
 die Wahrscheinlichkeiten der verschiedenen Wege zu
die Wahrscheinlichkeiten der verschiedenen Wege zu
 . Abbildung 6 zeigt, wie sich die Wahrscheinlichkeiten eines Zustandes aus allen
seinen direkten Vorgängern ergibt.
. Abbildung 6 zeigt, wie sich die Wahrscheinlichkeiten eines Zustandes aus allen
seinen direkten Vorgängern ergibt.
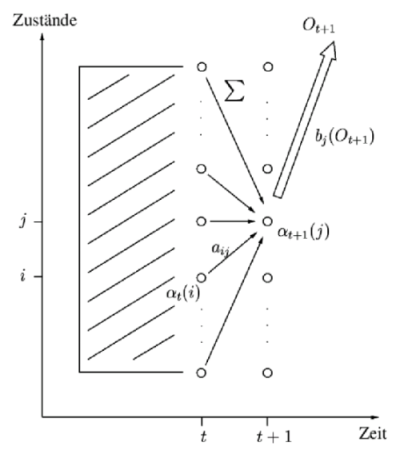 | |||
Abb. 7: Graphische Darstellung des Forward-Algorithmus. Fink, (2003) | |||
Als optimale Zustandsfolge wird die Folge von Zuständen eines HMM bezeichnet, die mit größter Wahrscheinlichkeit eine gegebene Folge von Observationssymbolen erzeugt. Formal lautet dies:
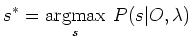 .
.
Mit Hilfe des Bayes'schen Gesetzes kann man die a priori Wahrscheinlichkeit, dass eine Zustandsfolge die gegebene Observationsfolge produziert, wie folgt berechnen:
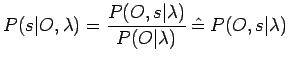 .
.
Dabei muss man beachten, dass der Nenner konstant ist, weil die Gesamtproduktionswahrscheinlichkeit
eines HMM bei gegebener Observationsfolge für alle Zustandsfolgen gleich ist. Deshalb
kann dieser weglassen werden.
Durch die Bestimmung der maximalen einzelnen Produktionswahrscheinlichkeit
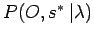 , erhält man die dazugehörige Zustandsfolge als die gesuchte optimale Zustandsfolge
, erhält man die dazugehörige Zustandsfolge als die gesuchte optimale Zustandsfolge
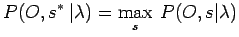 .
.
Dieser Algorithmus ist eine sehr effiziente Methode zur Berechnung der optimalen Zustandsfolge. Das Verfahren basiert ähnlich dem Forward-Algorithmus auf einem induktiven Ansatz. In einem Initialisierungsschritt betrachtet man alle Startwahrscheinlichkeiten der Zustände und multipliziert diese mit den dazugehörigen Emissionswahrscheinlichkeiten. Die resultierenden Produkte stellen die Wahrscheinlichkeiten der Startzustände dar, mit der sie das erste Symbol einer gegebenen Observationsfolge erzeugen. Für den Rekursionsschritt nimmt man an, den besten Zustandspfad bis zum aktuellen Zeitpunkt gefunden zu haben. Die Produktionswahrscheinlichkeiten für die Folgezustände ergeben sich dann durch Multiplikation mit den Übergangswahrscheinlichkeiten, gefolgt von einer Maximierung des Produktes. Somit wird der Pfad der optimalen Zustände iterativ verlängert. Anschließend wird noch die Emissionswahrscheinlichkeit hinzu multiplizieren. Zum Abschluss wählt man den Endzustand, der die größte Produktionswahrscheinlichkeit aufweist. Eine rekursive Rückverfolgung der Zustände und Übergänge, die zu dem Endzustand geführt haben, ergibt dann die optimale Zustandsfolge. Diese Rückwärtssuche nennt man auch backtracking. Formal lautet der Algorithmus wie folgt:
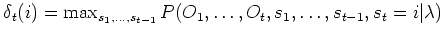
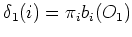 und
und
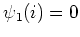
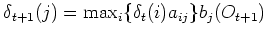 und
und
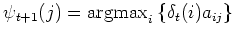
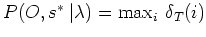 und
und

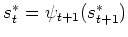
Ein Nachteil dieses Verfahrens besteht darin, dass die optimale Zustandsfolge erst nach vollständiger Verarbeitung der Observationsfolge bestimmbar ist. In der Abbildung 7 ist die Ähnlichkeit zum Forward-Algorithmus erkennbar. Im Rekursionsschritt wurde lediglich die Summenbildung in ein Maximierung umgewandelt.
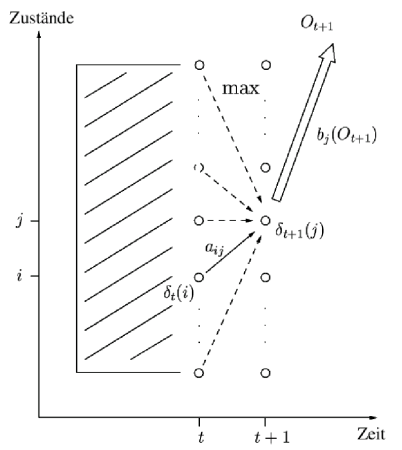 | |||
Abb. 8: Graphische Darstellung des Viterbi-Algorithmus. Fink, (2003) | |||
Die Effizienz und Qualität eines HMM hängt stark von der Güte
der statistischen Nachbildung des Problems ab. In vielen Fällen
ist dazu Expertenwissen absolut notwendig, z.B. bei der Wahl der Anzahl
der Zustände, Art der Emissionsverteilung und der Initialisierung der
Zustandswahrscheinlichkeiten. Oft kann man zu Beginn des Modelldesigns
noch nicht alle Parameter richtig wählen und erkennt erst bei der
Anwendung, welche Anpassungen vorgenommen werden müssen.
Deshalb trainiert man HMMs, um iterativ ein optimales Modell zu erhalten.
Das zugrundeliegende allgemeine Prinzip läßt sich folgendermaßen
zusammenfassen: Eine Wachstumstransformation verbessert die Parameter von
λ, so dass eine Bewertung des veränderten Modells
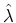 die von
die von
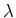 übertrifft. Mit anderen Worten wird Gesamtproduktionswahrscheinlichkeit des trainierten
HMM verbessert:
übertrifft. Mit anderen Worten wird Gesamtproduktionswahrscheinlichkeit des trainierten
HMM verbessert:
 .
.
Dieser Vorgang wird so lange wiederholt, bis keine Änderungen mehr messbar sind.
Dieses Optimierungsverfahren stellt den verbreitetsten Algorithmus zur
Parameterschätzung dar. Als Optimierungskriterium wird die Gesamtproduktionswahrscheinlichkeit
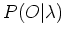 benutzt. Das heißt, die Parameter werden so verändert, dass
eine Trainingsmenge
benutzt. Das heißt, die Parameter werden so verändert, dass
eine Trainingsmenge
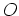 mit gleicher oder höherer Wahrscheinlichkeit als
erzeugt. Zunächst betrachtet man die Wahrscheinlichkeit bei gegebener Beobachtungsfolge
zum Zeitpunkt t im Zustand i und zum Zeitpunkt t+1 im Zustand j zu sein:
mit gleicher oder höherer Wahrscheinlichkeit als
erzeugt. Zunächst betrachtet man die Wahrscheinlichkeit bei gegebener Beobachtungsfolge
zum Zeitpunkt t im Zustand i und zum Zeitpunkt t+1 im Zustand j zu sein:
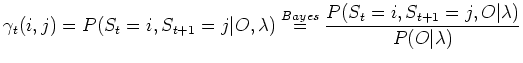 .
.
Durch Anwendung des Bayes'schen Gesetzes und entsprechender Umformung ergibt sich daraus:
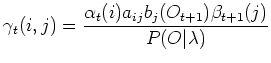
mit
als Analogon zu
.
Daraus lassen sich die neuen Parameter wie folgt ableiten:
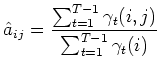
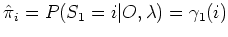
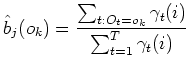 .
.
Dieses Verfahren kann alternativ zur Schätzung der HMM-Parameter verwendet werden. Grundlage bildet hier die Produktionswahrscheinlichkeit der optimalen Zustandsfolge
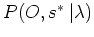 .
.
Dazu muss zunächst
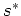 mittels Viterbi-Algorithmus bestimmt werden. Die
Schätzwerte für die neuen Parameter werden dann auf Basis empirischer Verteilungen ermittelt.
Diese erhält man durch explizite Zuordnung von Observationssymbolen
zu den Modellzuständen entlang des optimalen Zustandpfades.
mittels Viterbi-Algorithmus bestimmt werden. Die
Schätzwerte für die neuen Parameter werden dann auf Basis empirischer Verteilungen ermittelt.
Diese erhält man durch explizite Zuordnung von Observationssymbolen
zu den Modellzuständen entlang des optimalen Zustandpfades.
Die klassische Methode, Schlafstadien aus EEG-Aufnahmen zu bestimmen wurde
nach den Entwicklern Rechtschaffen & Kales (1968) benannt.
Als Aufnahmesignal werden die EEG-Signale der
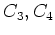 -Kanäle verwendet. Weiterhin werden die Aufnahmen des EMG (Elektromyogramm),
welches die Zuckungen der Nackenmuskulatur aufnimmt, und die des EOG
(Elektrookulogramm), welches die Bewegung der Augen registriert, analysiert.
Alle Eingangssignale werden in Intervalle von 30 Sekunden Länge
unterteilt. Dann ordnen Experten manuell die einzelnen Intervalle den
verschiedenen Schlafstadien zu. Dies erfordert einen hohen Zeitaufwand und
ruft viele Fehler durch subjektive Klassifikation hervor. Durch die relativ
großen Intervalle ergibt sich auch eine geringe Auflösung der Schlafanalyse.
Die Zuordnungsregeln der Signale zu den Schlafstadien sind bis jetzt nur
für junge Erwachsene dokumeniert.
-Kanäle verwendet. Weiterhin werden die Aufnahmen des EMG (Elektromyogramm),
welches die Zuckungen der Nackenmuskulatur aufnimmt, und die des EOG
(Elektrookulogramm), welches die Bewegung der Augen registriert, analysiert.
Alle Eingangssignale werden in Intervalle von 30 Sekunden Länge
unterteilt. Dann ordnen Experten manuell die einzelnen Intervalle den
verschiedenen Schlafstadien zu. Dies erfordert einen hohen Zeitaufwand und
ruft viele Fehler durch subjektive Klassifikation hervor. Durch die relativ
großen Intervalle ergibt sich auch eine geringe Auflösung der Schlafanalyse.
Die Zuordnungsregeln der Signale zu den Schlafstadien sind bis jetzt nur
für junge Erwachsene dokumeniert.
Im Folgenden wird ein Verfahren von Flexer, Sykacek, Rezek und Dorffner vorgestellt.
Ihr Ansatz soll die Probleme der R&K-Methode beheben. Dazu wurde nicht
versucht eine modifizierte Variante der R&K-Methode anzugeben, sondern Ziel
war, eine neue objektive Beschreibung des Schlafes zu finden. Man geht davon
aus, dass sich der Schlaf nur aus 3 statt 5 Schlafphasen zusammensetzt
(Wachphase, REM-Phase, Tiefschlaf-Phase).
Die anderen 2 Schlafphasen ergeben sich in diesem Ansatz als Überlagerung der 3
Hauptschlafphasen.
Bei den Versuchen wurden nur die
-Kanäle und das EMG-Signal verwendet. Zur Analyse lagen Aufnahmen von EEG- und
EMG-Signalen des Schlafes von 9 Probanden vor.
Insgesamt erstreckten sich die Aufnahmen über 70,5 Stunden von 5 Frauen und
4 Männern zwischen 20-60 Jahren. Diese Altersspanne ist unbedingt notwendig, da
vor allem der Anteil an REM-Schlaf stark vom Alter abhängig ist.
5 Aufnahmen wurden für das Training und 4 für die Evaluation benutzt.
Für das Training wurden nur die sichersten klassifizierbaren R&K-Schlafstadien
(Wachphase, REM-Phase, Tiefschlaf-Phase)
verwendet, weil nur diese einigermaßen sicher zugeordnet werden.
Die anderen Schlafphasen sollen wie oben erwähnt durch Mischung der 3 Hauptphasen
erzeugt werden. Damit man eine höhere Auflösung der Schlafanalyse erhält, werden Intervalle von
1 Sekunde der EEG- und EMG-Signale verwendet.
Der Lernvorgang erfolgte unüberwacht. Als vorverarbeitenden Schritt wurde das
EMG-Signal auf Frequenzen zwischen 20-45 Hz mittels FIR-Filterung reduziert.
GOHMM steht für Gaussian Observation HMM. Das heißt zur Klassifikation der EEG-Signale in die Schlafstadien (=Klassen) wurde ein HMM mit kontinuierlicher Ausgabewahrscheinlichkeit (Gaussche Beobachtung) verwendet. Dabei wird die Wahrscheinlichkeitsdichte des Observationssymbols für den Zustand j mittels einer Gaußverteilung angegeben:
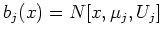 .
.
Dabei stellt
 eine Normalverteilung,
eine Normalverteilung,
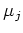 den Mittelwert und
den Mittelwert und
 die Kovarianzmatrix für den Zustand j dar.
Die 3 Hauptschlafstadien werden durch 3 Zustände repräsentiert.
Man verwendet nun den Viterbi-Algorithmus, um die optimale Zustandsfolge zu bestimmen.
Das heißt es wird die Folge an Schlafstadien gesucht, die mit größter
Wahrscheinlichkeit die aufgenommenen EEG- und EMG-Signale erzeugt.
die Kovarianzmatrix für den Zustand j dar.
Die 3 Hauptschlafstadien werden durch 3 Zustände repräsentiert.
Man verwendet nun den Viterbi-Algorithmus, um die optimale Zustandsfolge zu bestimmen.
Das heißt es wird die Folge an Schlafstadien gesucht, die mit größter
Wahrscheinlichkeit die aufgenommenen EEG- und EMG-Signale erzeugt.
Obwohl der hier vorgestellte Ansatz eine neue andere Ansicht der Schlafstadien vorschlägt, soll er mit der R&K-Methode verglichen werden, um Anhaltspunkte für die Korrektheit zu erhalten. In Tabelle 2 sieht man, dass lediglich die deep- und wake-Phase richtig erkannt werden. Die anderen weichen zum Teil stark von der klassischen Zuordnung ab.
| GOHMM | ||||||||
| wake |
|
|
|
deep | rem | |||
| wake | 86 | 11 | 0 | 0 | 0 | 3 | ||
| R |
|
52 | 22 | 6 | 6 | 0 | 13 | |
| & |
|
13 | 12 | 14 | 14 | 11 | 37 | |
| K |
|
2 | 2 | 17 | 20 | 51 | 8 | |
| deep | 1 | 0 | 4 | 14 | 81 | 0 | ||
| rem | 32 | 16 | 13 | 12 | 1 | 26 | ||
Tab. 2: Ergebnisse der GOHMM-Klassifikation mit der R&K-Methode. In den Spalten stehen die Klassifikationswahrscheinlichkeiten des GOHMM für einen EEG-Abschnitt, der mittels R&K-Methode in die Klasse in der linken Spalten eingeordnet wurde. Die Diagonale zeigt, mit welcher Wahrscheinlichkeit der GOHMM die gleiche Klassifikation wie die R&K-Methode erreicht. Flexer, Sykacek, Rezek, Dorffner, (2001) | ||||||||
Wegen der geringen Übereinstimmung wurde anschließend
versucht, das HMM nicht mit Daten der R&K-Phasen, sondern zufällig
zu initialisieren. Dies resultierte jedoch in noch größere Abweichungen.
Dies soll laut Angabe der Autoren die Theorie bekräftigen, dass der
Schlaf eine Mischung aus Tiefschlaf-, Wach- und REM-Phase ist. Der Versuch
zeigt allerdings lediglich, dass durch die Verwendung der 3 Hauptphasen eine
Verbesserung der Ergebnisse erzielt wird. Eine andere Initialisierung könnte
zu ähnlichen Verbesserungen führen.
Generell gibt es große Probleme, die REM-Phase von den Wach-,
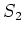 - und
- und
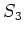 -Phasen zu unterscheiden. Dies kann man auf die fehlende Berücksichtigung der EOG-Signale
zurückführen, da diese zusammen mit den EMG-Signalen genaue Informationen über REM-Phasen
enthalten.
Ein Beispiel der Klassifikation (Abbildung 8) und die Histogramme der EMG-Signale
für die verschiedenen Schlafstadien (Abbildung 9) belegen
die Schwierigkeit der korrekten Klassifikation der REM-Phase.
-Phasen zu unterscheiden. Dies kann man auf die fehlende Berücksichtigung der EOG-Signale
zurückführen, da diese zusammen mit den EMG-Signalen genaue Informationen über REM-Phasen
enthalten.
Ein Beispiel der Klassifikation (Abbildung 8) und die Histogramme der EMG-Signale
für die verschiedenen Schlafstadien (Abbildung 9) belegen
die Schwierigkeit der korrekten Klassifikation der REM-Phase.
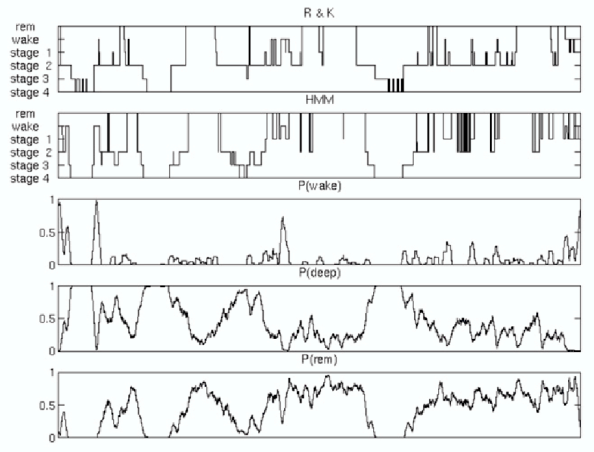 | |||
Abb. 9: Graphische Gegenüberstellung der GOHMM-Klassifikation und der R&K-Ergebnisse. Die oberen beiden Diagramme zeigen die Zuordnung der EEG-Signale während eines Schlafes zu den verschiedenen Schlafstadien mittels R&K-Methode bzw. mittels GOHMM. Die unteren drei Diagramme zeigen die Klassifikationswahrscheinlichkeiten des GOHMM für die Hauptschlafphasen der gleichen EEG-Aufnahme. Flexer, Sykacek, Rezek, Dorffner, (2001) | |||
 | |||
Abb. 10: Histogramme der EMG-Werte für die verschiedenen Schlafstadien; vor allem 1. bis 4. Schlafphase und die REM-Phase überlappen sich sehr stark. Flexer, Sykacek, Rezek, Dorffner, (2001) | |||
Ein weiteres Problem stellen die ungenauen EMG-Aufnahmen dar. Kleine feine Schwingungen der Muskeln wurden nicht aufgenommen und verfälschen die EEG-Aufnahme. Das ist auch ein Grund, die EOG-Daten in die Analyse mit einzubeziehen.